V našem datasatack modulu H3.0METRICS máme nové následující důležité funkcionality týkající se tahání dat z Meta Ads Transparency.
Nová metrika country_reach_total – DŮLEŽITÁ ZMĚNA!!
Dosud byla zásadní metrikou měření zásahu metrika eu_total_reach. Ta je definována jako “celkový zásah v EU”. Problém této metriky byl u situace, kdy jste chtěli vyselektovat jednotlivé země u mezinárodních kampaní.
Proto jsme zavedli novou metriku country_total_reach. Tato metrika obsahuje zásah pouze za zemi nebo skupinu zemí, které máte uvedeny v zadání DataTasku.
Například: pokud sledujeme klienta inzerujícího napříč více zeměmi EU, a vy zadáte datatask s omezením zemí na “CZ,SK”, budou metriky pro jednotlivé ady obsahovat: eu_total_reach: celkový zásah reklamy přes všechny země EU (i mimo CZ a SK) country_total_reach: celkový zásah reklamy ve vybraných zemích, tedy pouze CZ + SK
Metrika country_total_reach prevzala vůdčí roli pro enhanced data, tedy vypočítané imprese i spendy / cost metriky se nově odvíjí od country_total_reach a ne od eu_total_reach jak tomu bylo dosud.
V dashboardech, které zobrazují zadavatele inzerující napříč více zeměmi a vy chcete vizualizovat pohled na jednu konkrétní zemi doporučujeme vyměnit metriku eu_total_reach za novou country_total_reach.
Metrika est_cost_eur_ageweighted je nyní plně použitelná
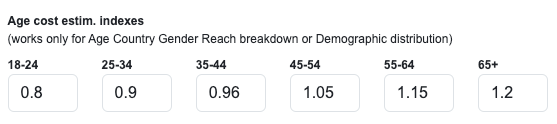
Po dostatečné době testování doporučujeme v datatascích adaptovat benchmarky indexů CPM pro jednotlivé věkové skupiny a poté používat novou metriku odhadu nákladů est_cost_eur_ageweighted.
Důvodem této vychytávky je situace, kdy někteří inzerenti ve sledované kategorii mají silnější cílení na některou věkovou skupinu a tím pádem je odhad jejich investic nepřesný.
V DataTasku si tedy můžete zadat indexy ceny pro jenotlivé věkové skupiny a index est_cost_eur_ageweighted je pak vypočítám tak, že odhad spendu počítá z reálně zasažených lidí v dané věkové skupině a indexu ceny pro danou skupinu.
Možnost nastavení search shody
V Datatascích je nově možnost nastavit typ “search shody” pro datatasky, které filtrují reklamy podle vyhledávání klíčového slova v textech reklam.
Klíčové slovo / klíčová slova se jako vždy vyplní do pole Search terms.
Pod tímto polem přibyl PullDown Search Type se dvěma hodnotami:
KEYWORD_UNORDERED tato volba způsobí, že každé slovo v Search terms bude bráno individuálně a vrátí výsledky, které obsahují tato slova v jakémkoliv pořadí
KEYWORD_EXACT_PHRASE bere sousloví v Search terms jako fráze a vrátí výsledky, které odpovídají přesně této frázi. Pro vyhledání vícero frází tyto oddělte čárkou, systém pak vrátí výsledky odpovídající přesné shodě pro každou z frází
Rozhodně, při zkušenostech s Meta API, doporučujeme otestovat různé varianty.
Možnost filtrování typu formátu
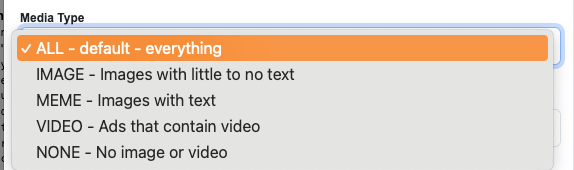
V nastavení datatasku přibyla nová možnost Media Type, kde se dá nastavit fitrování podle typu reklamního formátu. To se vám bude hodit například v případech, kdy chcete porovnávat SOV u pouze videoformátů.
V PullDownu můžete omezit typ formátů ve výjezdu dat následovně: ALL – všechny formáty IMAGE – pouze formáty s obrázkem a krátkým textem MEME – obrázky s textem VIDEO – reklamy s videem NONE – pouze textové reklamy
Až dosud se jednotlivé proměnné získané z datových zdrojů (Meta, Adform, Sklik, Google, H3.0, Social SOV = Ads Transparency data apod.) do cílových destinací (Google Big Query, interní databáze) posílaly tak, jak ze zdroje přišly. Většina proměnných byla v cílové databázi registrována jako STRING.
Co je nového?
Nyní jsme celou situaci vylepšili a je možné v rámci nastavení DataTasku jednotlivým sloupcům přiřadit datové typy podle názvů těchto sloupců v cílové databázi. Zároveň máme k dispozici předdefinované názvy sloupců s jejich doporučenými datovými typy.
Co se tím zlepší?
pohodlnější vizualizace – pokud máte v cílové databázi definovaný datový typ číslo, budou to tak brát vizualizační softwary (Looker Studio, Power BI, Tableau) rovnou a nebude nutné tento typ ve vizualizaci předefinovávat
lepší kompatibilita s Google Big Query, která má občas s datovými typy problémy
Jak nové datové typy nastavit?
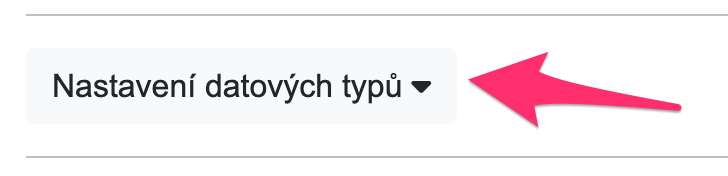
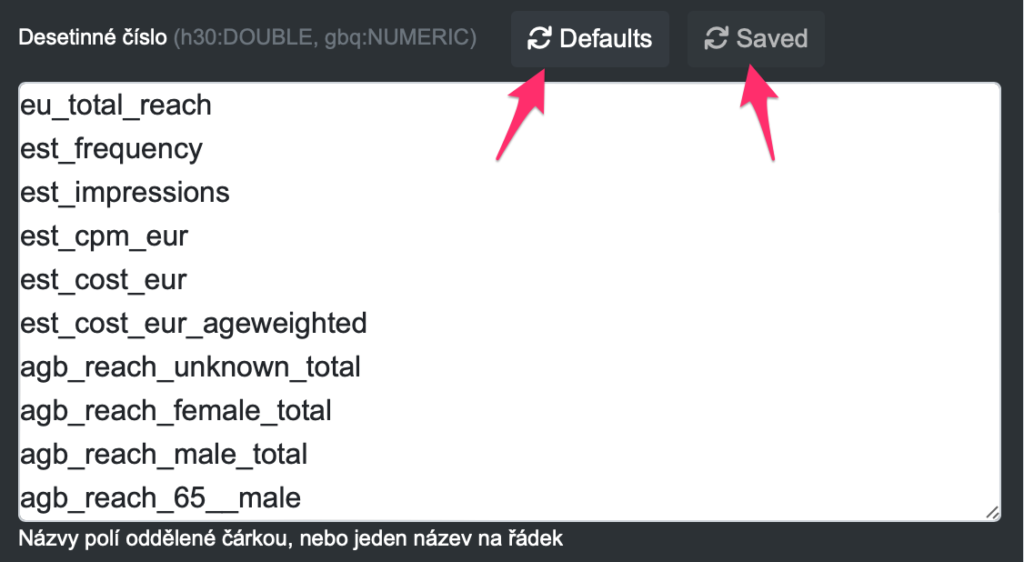
Při editaci nebo založení DataTasku je v dolní části formuláře k dispozici nové tlacítkom Nastavení datových typů.
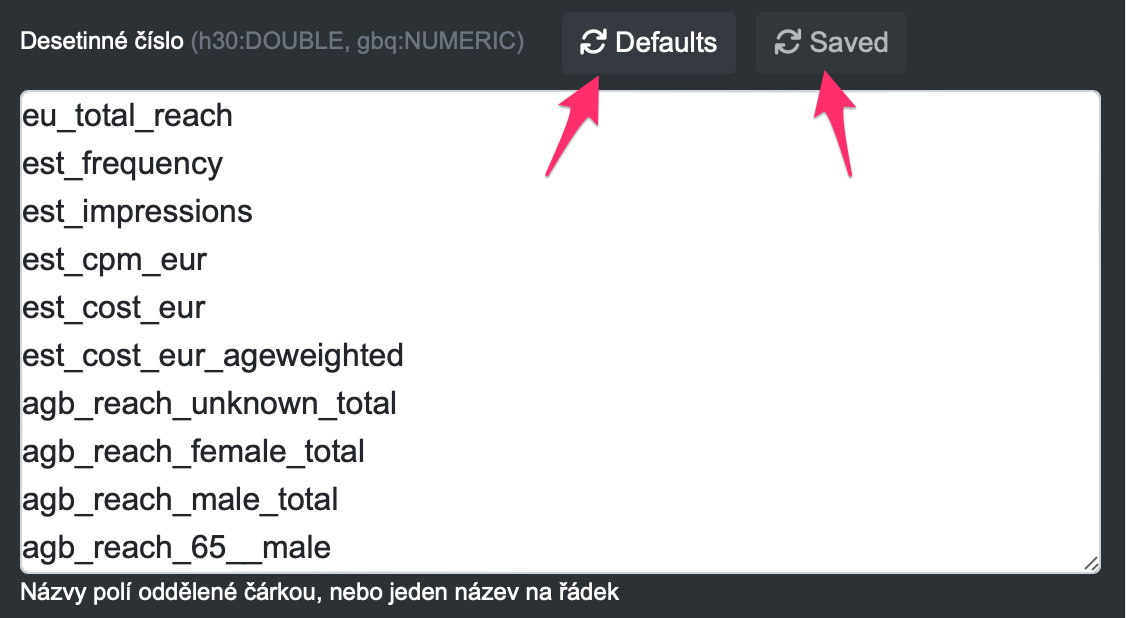
Po kliknutí na toto tlačítko se zobrazí 3 velké pole formuláře, kde se datové typy nastavují. Do každého pole formuláře se vkládají názvy sloupců v cílové databázi, které chcete uložit jako patřičný datový typ, který se určuje podle toho, ve kterém poli formuláře je proměnná napsána: – Desetinné číslo (MySQL DOUBLE, Google Big Query NUMERIC) – Celé číslo (MySQL BIGINT, Google Big Query INTEGER) – Datum (MySQL DATE, Google Big Query DATE)
Pokud kliknete na tlačítko “Default” u daného pole formuláře, vloží se do daného pole námi předvybrané názvy sloupců. Pokud poté kliknete na tlačítko Saved, vrátí se do pole hodnoty, které máte aktuálně u DataTasku uložené.
V případě, že název sloupce nezvolíte do žádného z těchto polí, bude do databáze vloženo jako STRING.
Defaultní názvy sloupců máme zatím zprovozněné pro následující zdroje dat: – H3.0 Campaigns and Placements – META Ad Transparency – GBQ Ad Transparency
Nekolik důležitých poznámek pro přechod na tuto novou funkci:
Funkce nastavení datových typů sloupců funguje nejlépe u nově vytvořených tabulek. Pokud byste chtěli měnit již naplněnou tabulku, nemusí být funkce v této operaci úspěšná. Proto pro zavedení této funkce doporučujeme založit nové tabulky v databázi (nebo ty předchozí vyprázdnit i vymazat strukturu).
Ve starých DataTascích (ty před update, které tuto novinku obsahuje) zůstane vše jako dřív, ale při jejich editaci se systém pokusí vám nastavit nové datové typy. Pokud je nechcete a potřebujete DataTask změnit a uložit, prostě je z daných polí vymažte.
Upozornění!!
Pokud nastavíte cílový datový typ, který není kompatibilní s hodnotou proměnné, například pokud je proměnná campaign_name na vstupu “STRING”, má hodnotu “Velká kampaň” a vy se z ní pokusíte udělat číslo nebo datum, bude hodnota v cílové databázi nesmyslná / nulová.
V případě, že máte aktivovaný (a zaplacený <3 ) modul H3.0METRICS, může se vám hodit tento jednoduchý návod pro začátečníky na to, jak si připravit díky H3.0METRICS jednoduchý dashboard s přehledem kampaně v Adformu.
Příklad je na Adformu, ale je jednoduše aplikovatelný i na ostatní statistické systémy dostupné v H3.0METRICS jako Meta, Sklik apod.
Dashboard budeme vytvářet v Google Looker Studiu (ex Google Data Studio), ale je jednoduše aplikovatelný i na ostatní vizualizační systémy jako například Tableau či PowerBI.
Celý postup se sestává z následujících kroků: 1) Nastavení Google Big Query 2) Nastavení DataTasku v H3.0METRICS 3) vytvoření dashboardu v Google Looker Studio
Přístup do Google Big Query na frontend i zadaný v H3.0 [v Návodu zde je to část PROPOJENÍ H3.0 A GBQ]. Pokud nemáte vlastní GBQ a chcete ji od nás, umíme poskytnout, stačí nás kontaktovat.
A nyní již pojďme k našemu návodu
1) Nastavení Google Big Query (GBQ)
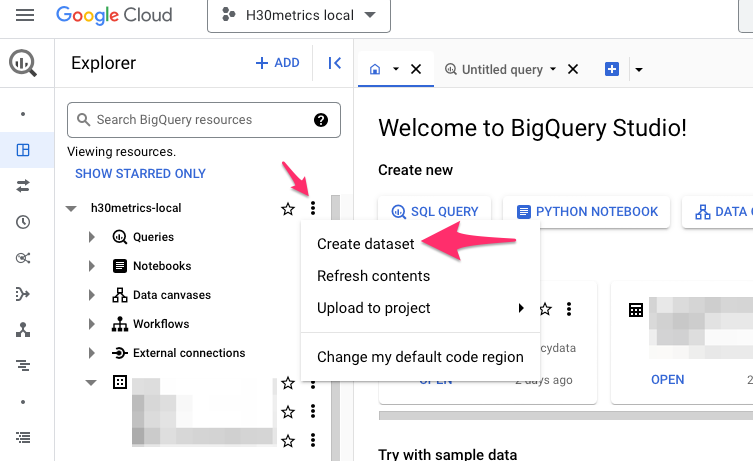
V GBQ si v https://console.cloud.google.com/ vyberte projekt, ve kterém chcete ukládat data statistik kampaní, klikněte na hamburger menu vlevo vyberte Big Query / Big Query Studio. Ve sloupci Explorer pak klikněte na tři tečky u daného projektu a vyberte “Create dataset”.
Dataset je v GBQ takový adresář s datovými tabulkami. My si pro náš příklad vytvoříme dataset s názvem “CampaignData”. Když vytváříte dataset, stačí vyplnit jeho název = Dataset ID a potvrdit.
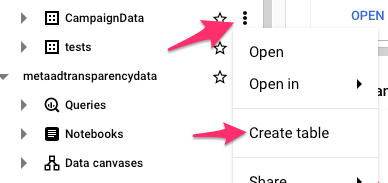
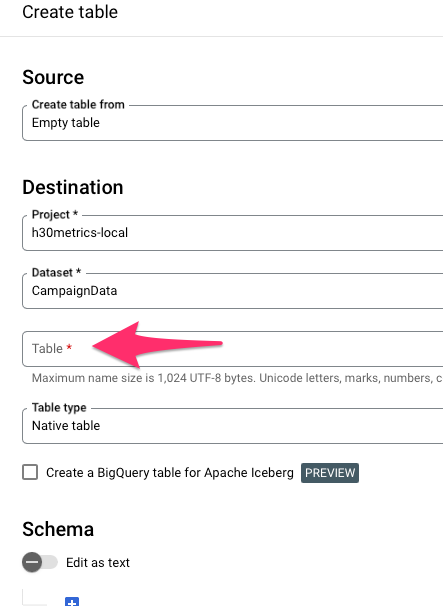
Nyní si v našem novém datasetu vytvoříme tabulku pro Adform data. Ve velkých projektech budete mít systém tabulek s různými pohledy na data. Ty budou odviset podle toho, co v dashboardech chcete všechno zobrazovat. My si pro náš jednoduchý příklad vytvoříme tabulku, kde budou data Adformu po adsetech a po dnech, takže vytváříme tabulku “ADF_AdsetsDaily”. Vytvoříme ji tak, že kliknetme na tři tečky v řádce s názvem datasetu a vybereme Create table.
V okně, které se objeví stačí vyplnit pouze kolonku “Table” (má červenou hvězdičku) kam vyplníte název tabulky, tedy “ADF_AdsetsDaily” a klikneme na tlačítko Create Table.
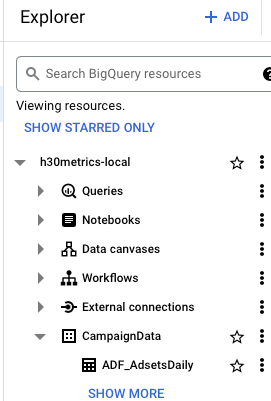
Nyní tedy máme vytvořen dataset CampaignData a pod ním tabulku ADF_AdsetsDaily tak, jak je vidět níže na obrázku.
A můžeme se přesunout do H3.0
2) Nastavení DataTasku v H3.0METRICS
DataTask v H3.0METRICS nám umožní tahat data z Adformu přes H3.0 do Google Big Query. Dělá se to přes takzvané Data Tasky, což jsou vlastně jednotlivé definice pohledů na data, která chceme stahovat ze statistického systému a posílat do GBQ.
Data Tasky je možné pro lepší evidenci shlukovat do Data Projektů, to ale pro tento případ vynecháme a vrhneme se rovnou na vytvoření Data Tasku.
V menu H3.0METRICS / Data Tasks klikneme na tlačítko Vytvořit nový DataTask. Dostáváme se do komplexního formuláře, který umožňuje mnoho nastavení DataTasku. Pro naši potřebu vyplníme formulář následovně:
V horní části Frekvence spouštění překlikneme DAY na hodnotu * a poté hour na 23. To nám zajistí každodenní spouštění tohoto DataTasku ve 23 hodin, tedy budeme mít vždy čerstvá data.
Níže si zaškrtneme Odeslat report po NEúspěšném provedení (a o pole výáše vyplníme e-mail), abychom byli informováni, pokud se něco podělalo.
Nyní je nutné nastavit dvě části a to Zdroj dat a Cílové propojení
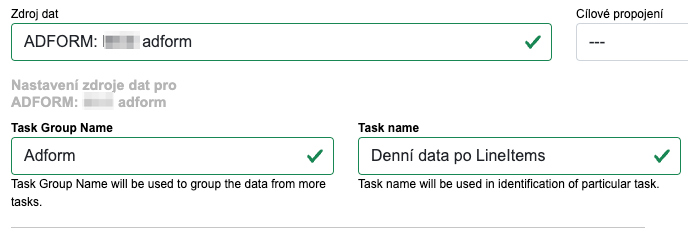
V PullDown menu Zdroj dat vybereme část ADFORM a patřičný login. Tím se nám otevře celá levá část formuláře, kde je možné nastavit různé pohledy na data v Adformu.
Začneme vyplnení Task Group Name a Task Name, což jsou evidenční pojmenování daného DataTasku, abychom věděli co dělá již z názvu. My si to pojmenujeme dle obrázku níže
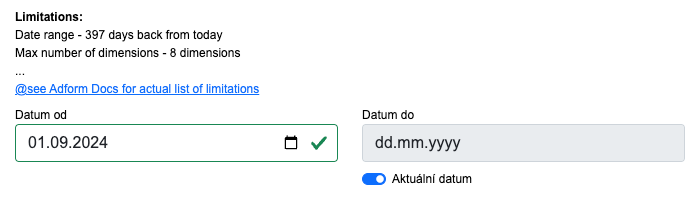
Nyní vybereme, od kdy chceme data sbírat. Nám začíná kampaň 1.9.2024, takže v levém poli vybereme toto datum. Zároveň chceme, abychom data sbírali vždy k aktuálnímu datu kdy se DataTask spouští, takže necháme v pravém datumu zaškrtnuto “Aktuální datum”. Pokud bychom chtěli data stáhnout z období OD-DO, dáme do pravého datumu hodnotu DO.
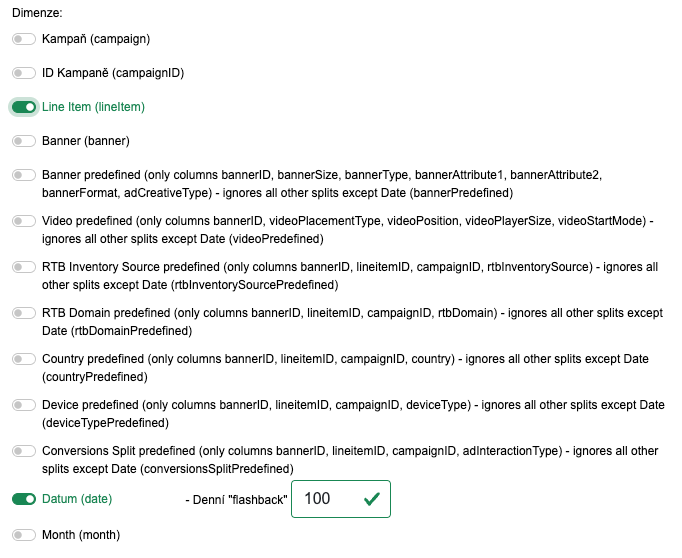
Nyní si nadefinujeme možné splity (Dimenze) dat. V Adform je hodně zaškrtávátek a je důležité vědět, že API Adformu je poněkud citlivější na různé kombinace kombinací, takže když toho zaškrtnete více, může vás API vyfáknout s tím, že používáte nepovolenou kombinaci. Na zjištění kompatibility není nějaký nástroj, takže pokud vám vaše kombinace nepůjde, nezoufejte a buď zkuste jinou kombinaci, nebo nám dejte vědět a my vám řekneme jak na to.
Pro naši potřebu použijeme split po Line Item a po dnech, tedy budete mít zaškrtnuto jenom to co máme níže na obrázku.
V H3.0METRICS napojení na statistické systémy je často možné počítat s takzvaným flashbackem, což je pokročilé nastavení pro velké objemy dat, kdy se při opětovném spouštění datatasku nenatahuje například celý rok, ale pouze posledních X dní, kde to X je nastaveno v hodnotě flashbacku. Pro první spuštění DataTasku je důležité, abyste měli hodnotu flashbacku nastavenou tak, aby postihovala celou kampaň, tedy X dní nazpět bylo před začátkem kampaně.
Tím máme nastavenou podobu zdroje dat a přejdeme k Cílovému propojení, tedy k PullDown menu na pravé straně formuláře.
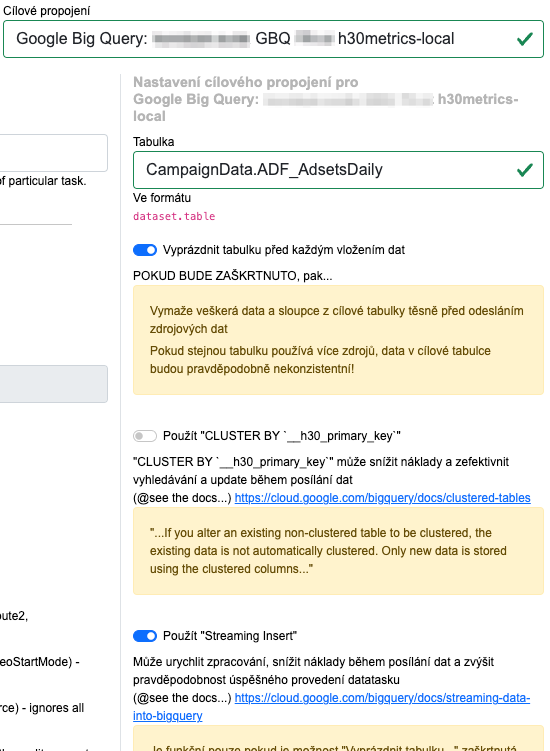
Zde vyberte v sekci Google Big Query patřičný login, který má práva k projektu, ve kterém jste na začátku založili dataset a tabulku v GBQ.
Do pole Tabulka zadejte hodnotu názvu datasetu a tabulky tak, že je oddělíte tečkou, takže v našem případe to bude CampaignData.ADF_AdsetsDaily
V zaškrtávátkách níže je velmi doporučeno nechat zaškrtnutý checkbox Použít “Streaming insert”, který umožňuje rychlejší vkládání dat s nižšími náklady na GBQ. Má malou nevýhodu – příkazy na stejnou tabulku nejdou opakovat hned po sobe, potřebují cca 30-60 minut odstup.
Také je nutné si vybrat, zda budete chtít zaškrtnout první checkbox “Vyprázdnit tabulku před každým vložením dat”. Toto u velkých stabilních datových projektů s rozumně nastavenou hodnotou flashbacku a neměnnou strukturou doporučujeme nezaškrtnout, ale pro menší data kde i často testujete výstupy to nechme zaškrnuté. Pravý sloupec formuláře pak vypadá takto:
Po tomto zadání ještě doporučujeme kliknout na tlačítko Test cílového propojení (umístěné úplně vpravo dole ve formuláři), které zkontroluje, zda cílová tabulka v GBQ existuje. Výsledek se objeví jako malý modal v pravé horní části obrazovky.
Nyní tlačítkem Save v levé dolní části formuláře DatTask uložte.
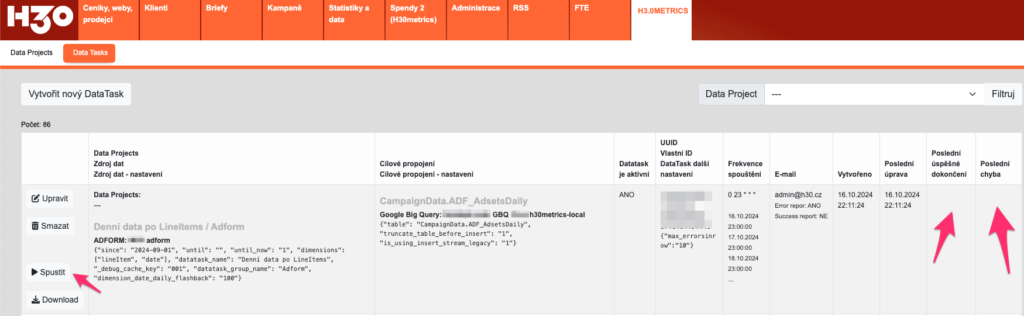
DataTask poté spustíte kliknutím na tlačítko Spustit v řádce DataTasku. Upozorňujeme, že DataTask může trvat od cca 10 minut (pro menší účet na kratší období a málo kampaněmi) až po několik hodin pro velké účty s mnoha kampaněmi a vámi psychotiky, kteří jste vybrali velké množství dimenzí dat, takže se vám generují miliony (doslova) řádků, které sice nikdy nikdo nebude analyzovat, ale vy máte pocit, že jste data scientisti.
To, jak DataTask běží je možné sledovat v Administrace/Log, kde se vypisuje jak to jde. Zároveň v řádku DataTasku v jejich seznamu jsou sloupce Poslední úspěšné dokončení a nedejbože Poslední chyba, kam se vypisuje výsledek spuštění tohoto pokladu.
DataTasky běží asynchronně, takže pokud jste ho spustili, můžete jít dělat v H3.0 něco jiného a nepřerušíte ho, můžete se sem za pár minut vrátit.
No a až se vám objeví datum ve sloupci Poslední úspěšné dokončení, můžeme se přesunout k tvorbě dashboardu.
3) vytvoření dashboardu v Google Looker Studio
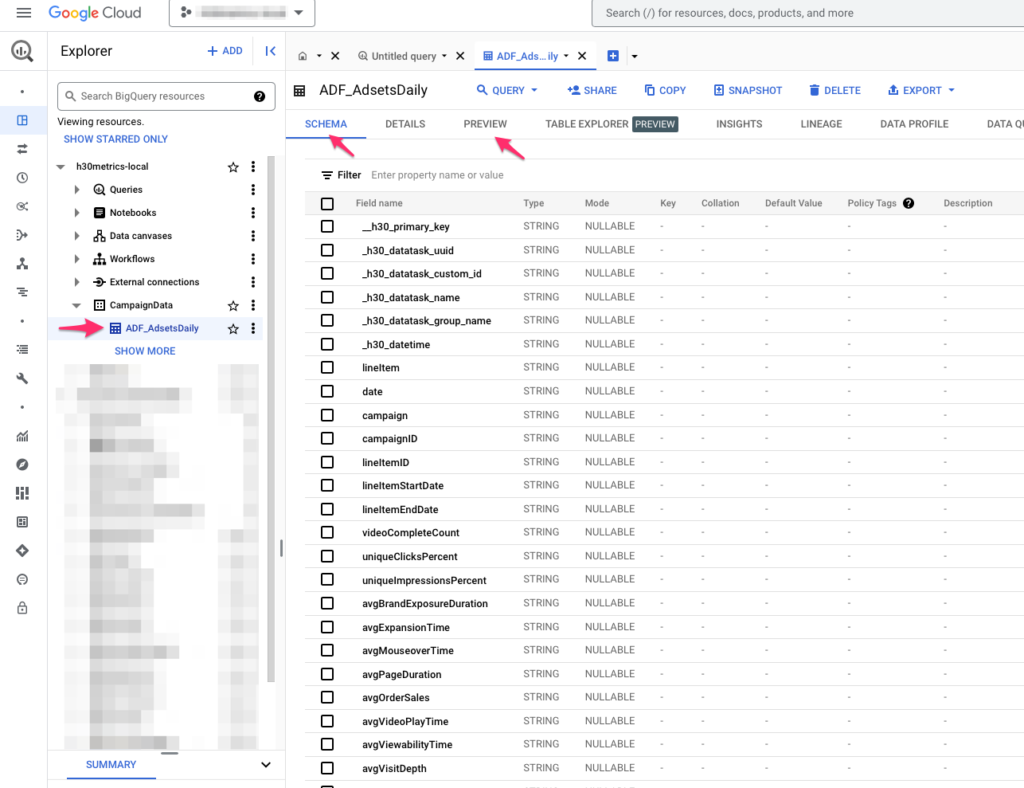
Pro tvorbu dashboardu si otevřete dvě okna browseru. V jednom si otevřete GBQ s vaším projektem. Tam se dostanete stejně jako když jsme vytvářeli Data Set a tabulku, akorát na tu tabulku kliknete a v pravém okně se vám objeví detaily tabulky. Budete se dívat jak na záložku SCHEMA, kde jsou hezky vidět sloupce tabulky, tak na záložku PREVIEW, kde jsou vidět data.
Tyto pohledy se vám budou dost hodit k tomu, abyste věděli jaká všechna data můžete v dashboardu vizualizovat.
Nebudeme se zabývat detaily práce s Looker Studiem, na to se podívejte na nějaké výukové zdroje, například zde. Ale ukážeme vám jak na to.
Je velmi důležité, abyste se do Looker připojili pod loginem, který má dostatečná práva do Google Big Query.
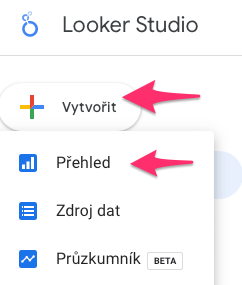
V Looker studio klikněte na velké tlačítko Vytvořit umístěné vlevo nahoře a vyberte možnost Přehled.
Tím vytvoříte dashboard.
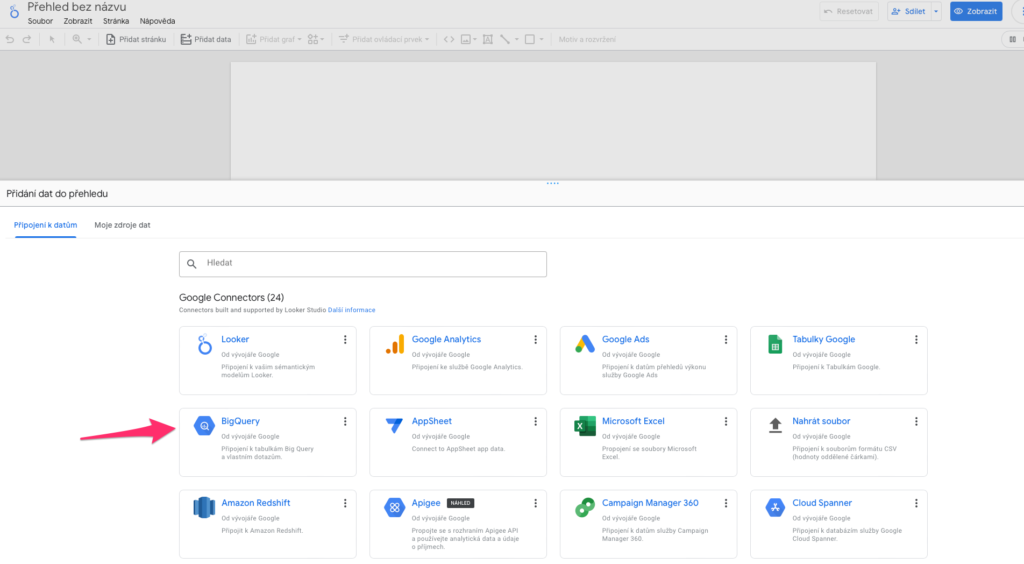
Hned v úvodu to po vás bude chtít připojit nějaký zdroj dat, tedy naši vytvořenou tabulku. V možnostech si vyberte Big Query.
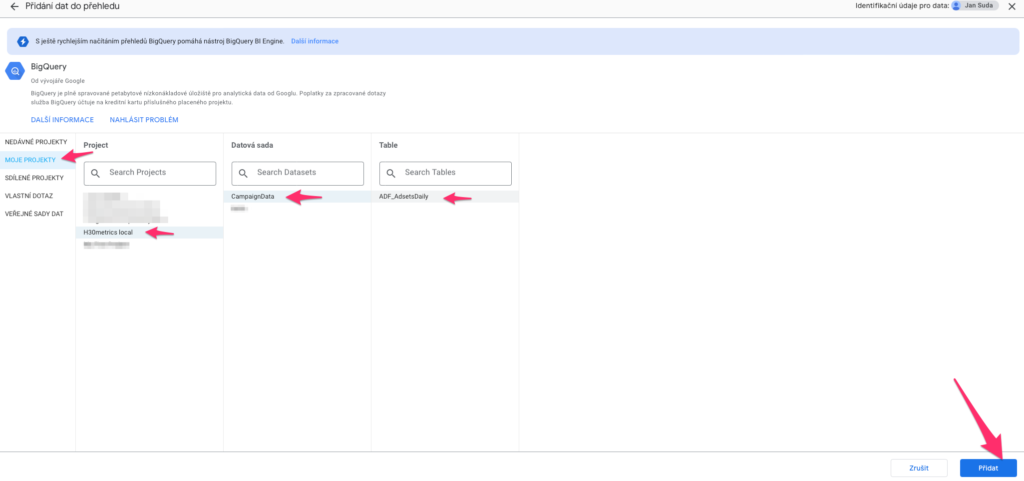
Nyní je třeba vybrat naši tabulku, takže zleva vybírejte MOJE PROJEKTY, název GBQ projektu, název GBQ datasetu a ve finále klikněte na název GBQ tabulky a poté na tlačítko Přidat vpravo dole.
Looker se vás pak ještě asi zeptá, zda chcete přidat data do přehledu, tak klikněte jako že ano. Mělo by se vám pak objevit hlavní okno Looker Studia. Nyní tedy máte připojené statistiky Adformu do dashboardu a čekají nás další dva kroky: a) příprava dat b) konečně nějaké vizualizace.
Příprava dat se sestává ze dvou částí. Nejdřív si upravíme správné datové typy u jednotlivých sloupců a poté si dopočteme indexy.
Po kliknutí na menu Zdroj / Spravovat přidané zdroje dat se vám zobrazí přehled napojených zdrojů dat a vy v řádce s adformí tabulku klikněte na UPRAVIT.
Objeví se vám struktura dat naší Adformí tabulky.
Teď nás čeká taková klikací práce, kdy se podíváme na sloupce tabulky a u všech číselných sloupců změníme v Pulldownu hodnotu “Text” na hodnotu Numerický – Číslo.
Je to trošku ojeb s klikáním, ale aspoň budete mít pocit, že jste skutečně pro ten dashboard něco udelali.
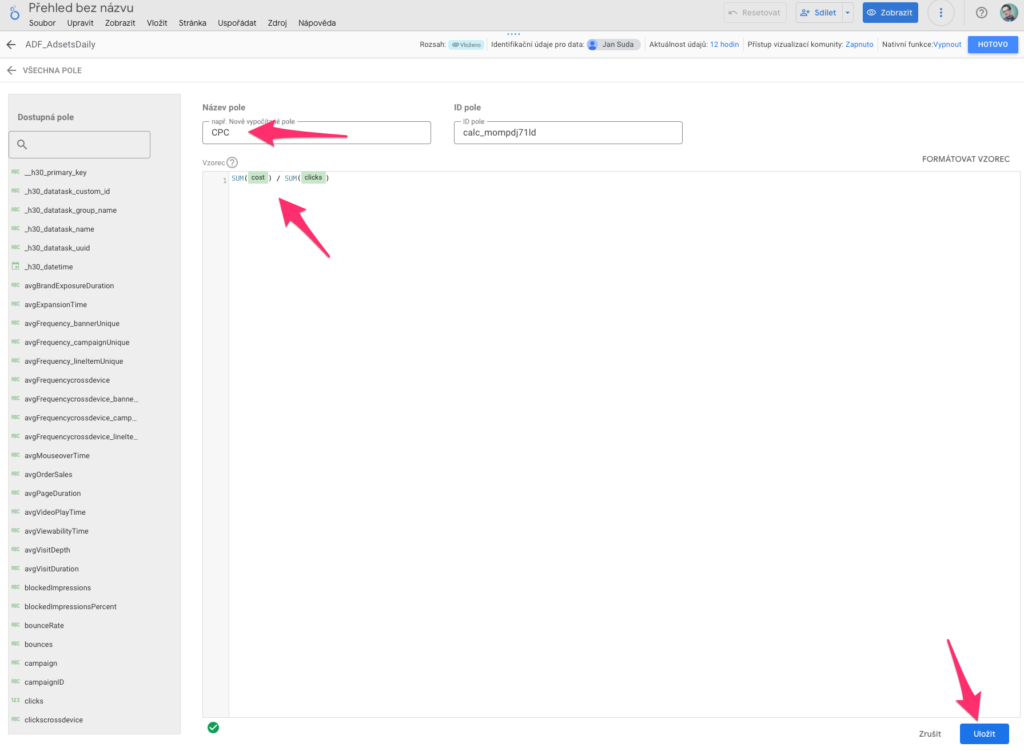
Dále je nutné si nastavit přepočtové indexy. Při datové vizualizaci totiž nemůžete počítat s indexy jako CPC, CPM nebo CTR z datové tabulky, protože ty jsou platné jenom při nejdetailnější granularitě dat, ale vy při vizualizaci častu grupujete data dohromady, takže je lepší je vypočítat ručně. Ukážeme si, jak se nastaví CPC, ale vy si v reálu nastavte všechny přepočítané indexy.
Klikněte na PŘIDAT POLE vpravo nahoře a vyberte možnost Přidat vypočítané Pole.
Tím si přidáte vypočítaný sloupec tabulky. My chceme CPC, tedy do Název pole vyplníme CPC. Do pole vzorec pak přidáme vzorec, který nám vypočítá cenu za kliknutí, tedy: SUM(cost) / SUM(clicks) Poté klikněte na tlačítko Uložit vpravo dole.
Toto opakujte pro všechny přepočtové indexy, které chcete ve vizualizaci mít.
Až to budete mít hotové, klikněte na HOTOVO v pravé horní části a poté co se vám zobrazí seznam datových zdrojů na ZAVŘÍT taktéž v prvé horní části. Tím se dostanete zpět do hlavního pohledu Looker Studia kde si konečně už vytvoříme nějaké elementy dashboardu.
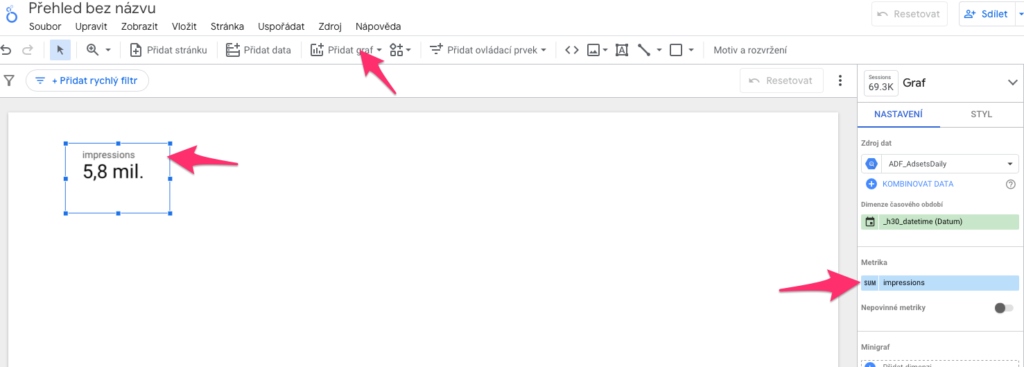
Celková suma impresí
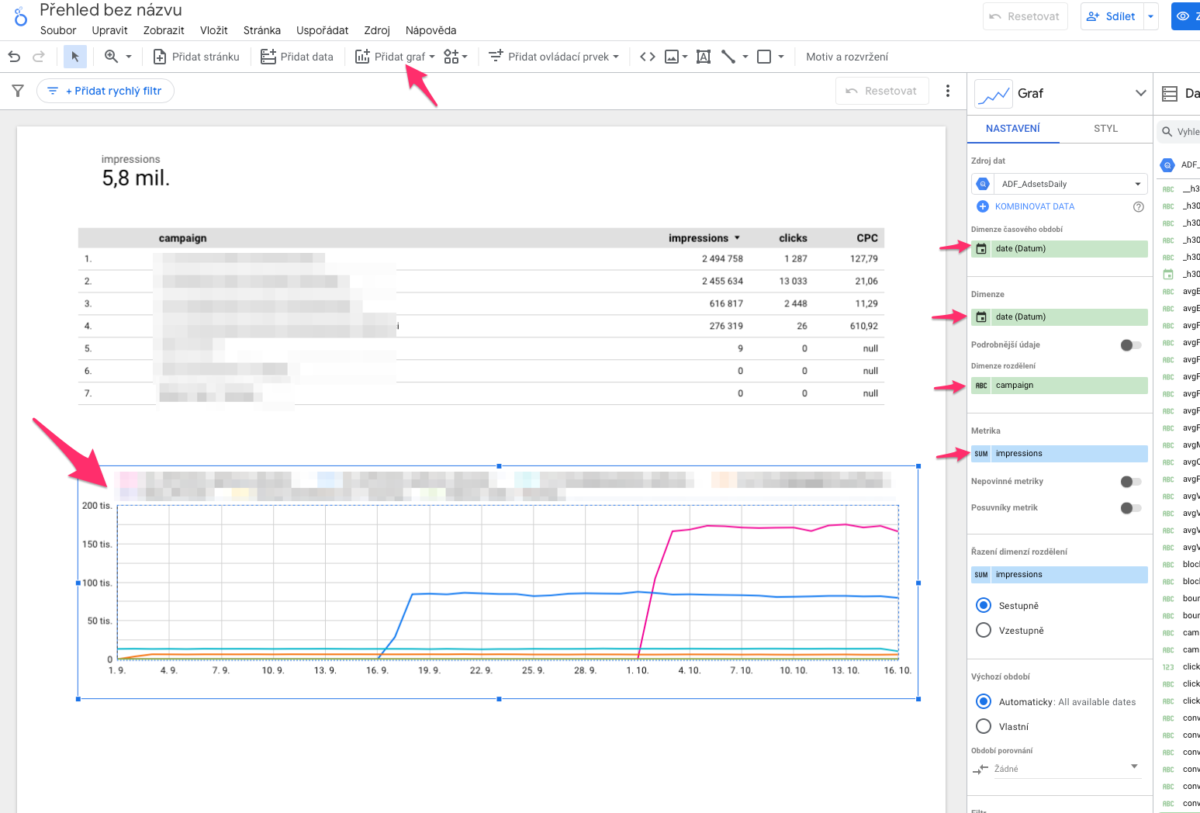
Klikněte na Přidat graf a vyberte Rychlý přehled s kompaktními čísly. Vloží se vám element do dashboardu. Jenou na něj klikněte. V pravém sloupci Nastavení vyberte jako Metrika “impressions” (vyberete to tak, že kliknete na název té metriky co tam byla na začátku a v seznamu najdete impressions a kliknete na to . A máte hotovo.
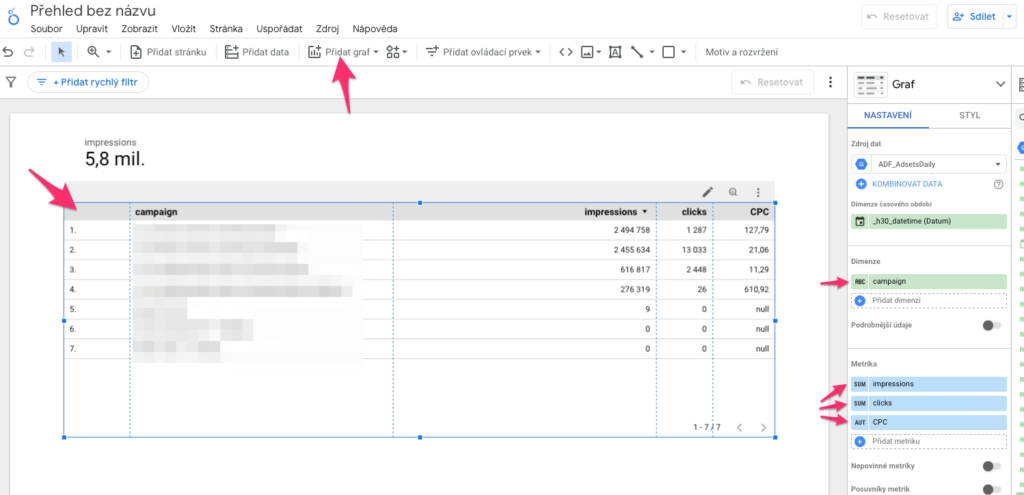
Tabulka přehledu kampaní
Klikněte na Přidat graf a vyberte Tabulka. Klikněte v dashboardu na místo, kam chcete tabulku vložit. Můžete si ji roztáhnout jak chcete. V pravém sloupci Nastavení jsou sekce Dimenze a Metriky.
V Dimenze klikněte na aktuální název dimenze a místo ní vložte pouze “campaign”.
V Metriky vyberte a přidejte libovolné množství metrik, které chcete v tabulce mít.
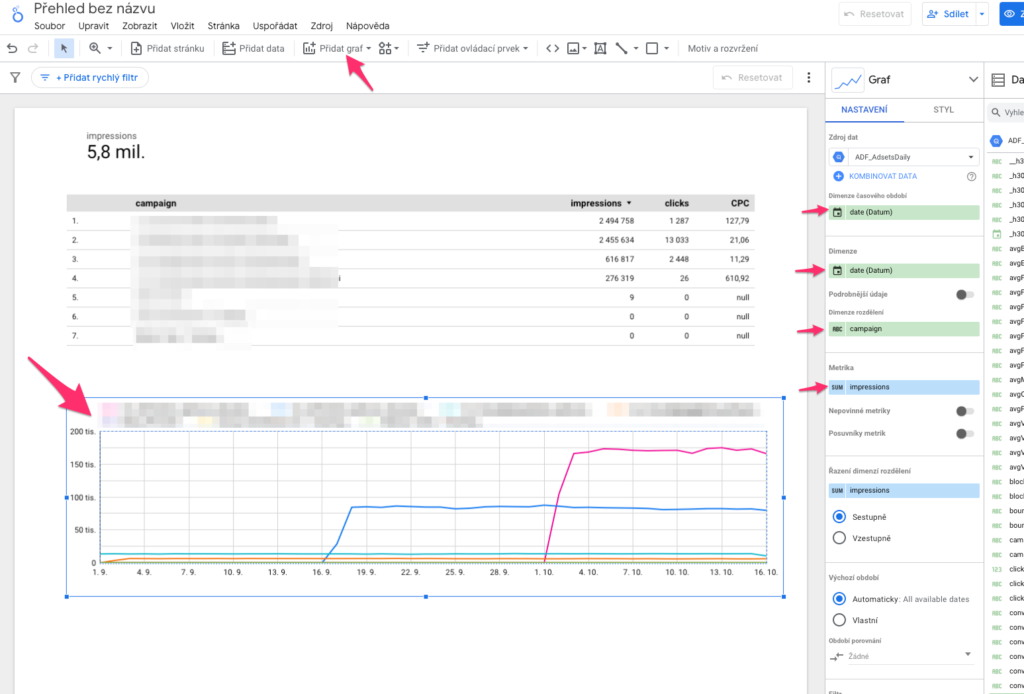
Graf vývoje impresí
Klikněte na Přidat graf a ze sekce Časové řady vyberte Graf časové řady. Klikněte v dashboardu na místo, kam chcete graf vložit. Můžete si ho roztáhnout jak chcete. V pravém sloupci Nastavení jsou sekce Dimenze časového období, Dimenze a Metriky.
V Dimenze časového období klikněte na aktuální název dimenze a místo ní vložte pouze “date”. (je tam několik datumů, ale vy chcete pro Adform ten, co se jmenuje pouze “date”.
To samé “date” vyberte v Dimenze hned pod nadpisem Dimenze.
V sekci Dimenze ještě v Dimenze rozdělení můžete vybrat “campaign” v případě, že chcete mít v grafu rozdělený vývoj impresí po kampaních.
V Metriky vyberte namísto aktuální metriky “impressions”.
Poznámka: správně byste ve všech elementech dashboardu měli mít v tom Dimenze časového období hodnotu “date” stejně jako jsme to teď nastavili v tom grafu. Pomůže vám to pak při případných interakcích či výběrech času.
A to je vše, máte základní dashboard hotový a nyní si s tím můžete hrát.
Tento návod ukazuje, jak nastavit H3.0 METRICS DataTask pro Google Ads Transparency data tak, aby dokázal vyhledávat podle URL cílové landing page či textu reklamy, což je nová funkcionalita, která nebyla možná od začátku.
Zatímco na frontendu Google Ads Transparency jsou obe možnosti vyhledávání podle Advertisera (majitele Google Ads účtu) i podle cílové domény, v datech, které Google poskytuje tato možnost není = v datech je u kreativy pouze advertiser a není tam žádní informace o textu ani cílové URL reklamy. To způsobovalo problémy zejména ve dvou oblastech: 1) pokud spravoval advertiser pod svým účtem více značek, byly tyto dohromady 2) z dat nebylo dobře možné dostat všechny advertisery, kteří pouštěli reklamy na danou značku
Nyní jsme tuto možnost uvedli v činnost, a to díky zapojení SERPAPI služby. Bohužel je SERPAPI placená, ale pro rozumné zákazníky umíme nasdílet náš placený účet. Takže nás pro loginy kontaktujte.
Vše ostatní je již jednoduché
Založení DataTasku
Formulář pro založení Google Ads Transparency (Zdroj dat: GBQ Ad Transparency: ) DataTasku byl obohacen o 3 nové elementy:
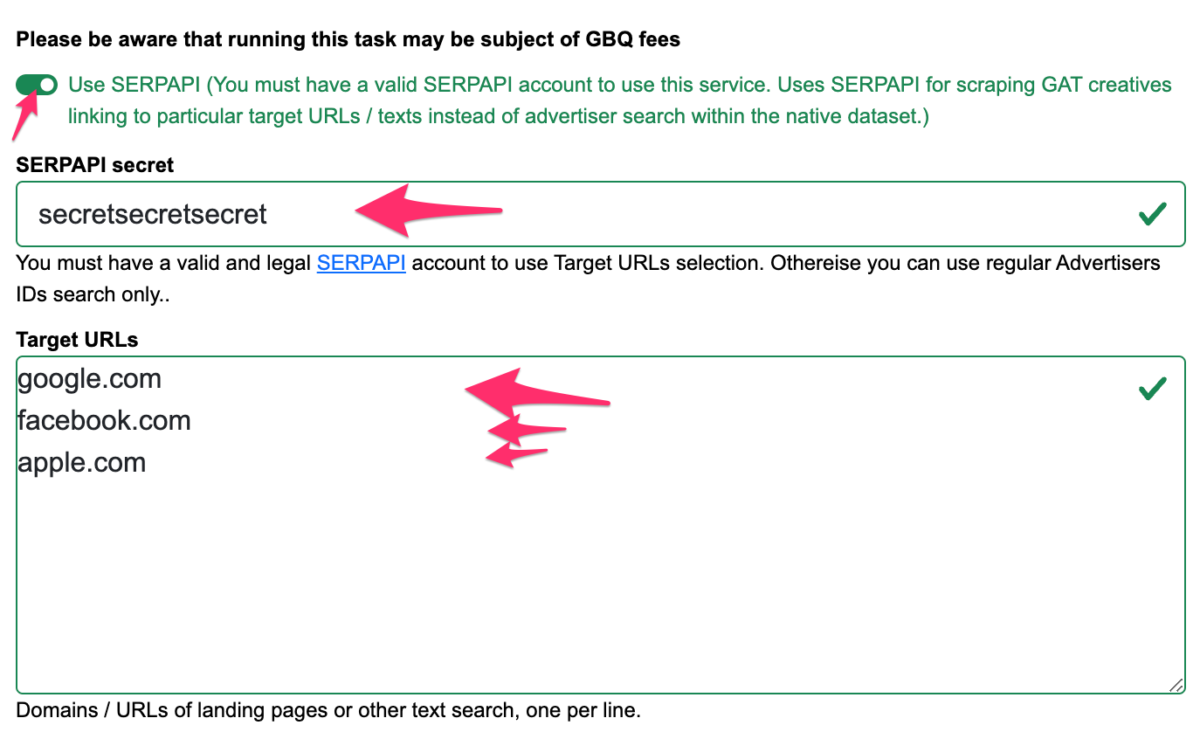
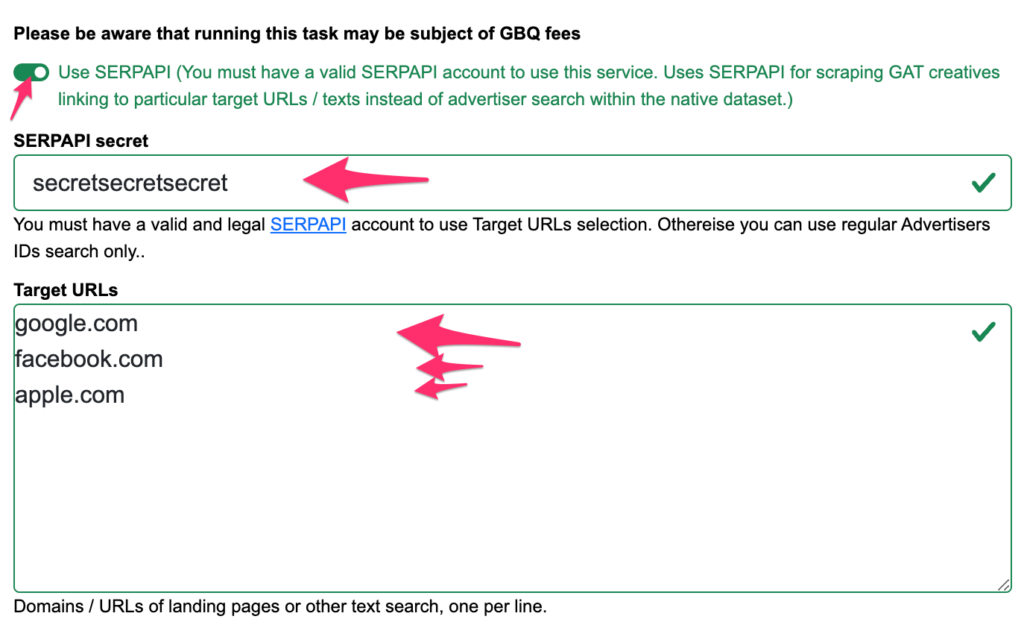
Checkbox “Use SERPAPI” – tento checkbox zaškrtněte pokud chcete vyjet data pro vyhledávání cílových domén nebo textů reklam.
SERPAPI secret – API key, který buď dostanete odd nás, nebo si můžete vytvořit svůj vlastní SERPAPI účet a v něm si API key vytvořit.
Target URLs – pole pro uvedení všech cílových URL (nebo textů reklam), které chcete v rámci tasku vypsat. Dává se jedno URL / text na řádek a logika mezi řádky je NEBO, tedy výsledek pak bude obsahovat souhrn výsledků pro vyhledávání každého řádku.
Výstupní data pak obsahují všechny reklamy všech advertiserů, kteří danou doménu v daném období na Google propagovali.
Tento přístup je možné kombinovat i s dosud platnými omezeními, tedy filtr dle skupiny advertiserů. Můžete si tak do datasetu poslat data za doménu neco.cz a zároveň od advertisera XXXXX.
Změny ve výstupních datech
Výstupní data pak obsahují 2 nové sloupce:
target_url – sloupec obsahuje cílové URL (nebo text reklamy) dané kreativy, který jste zadali v datatasku. Na tento sloupec je možné namapovat Share of Voice grafy, pokud chcete switchnout z pohledu “per advertiser” na pohled “per brand”.
image – u některých textových reklam umíme získat i screenshot této reklamy. Pokud tento umíme získat, bude jeho URL jako hodnota tohoto sloupce. Image ale rozhodně není možné získat od všech reklam.
Kompletně jsme předělali modul SPENDY, aby vyhovoval moderním potřebám paranoidních data expertů. Nyní modul umožňuje přehledný pohled na data.
Nový modul SPENDY vyžaduje pár kliknutí pro jeho nastavení, tomu se věnujeme níže v článku.
Zásadní změnou jsou dva úhly pohledu, které si můžete libovolně nastavovat:
SPLIT
FILTROVÁNÍ
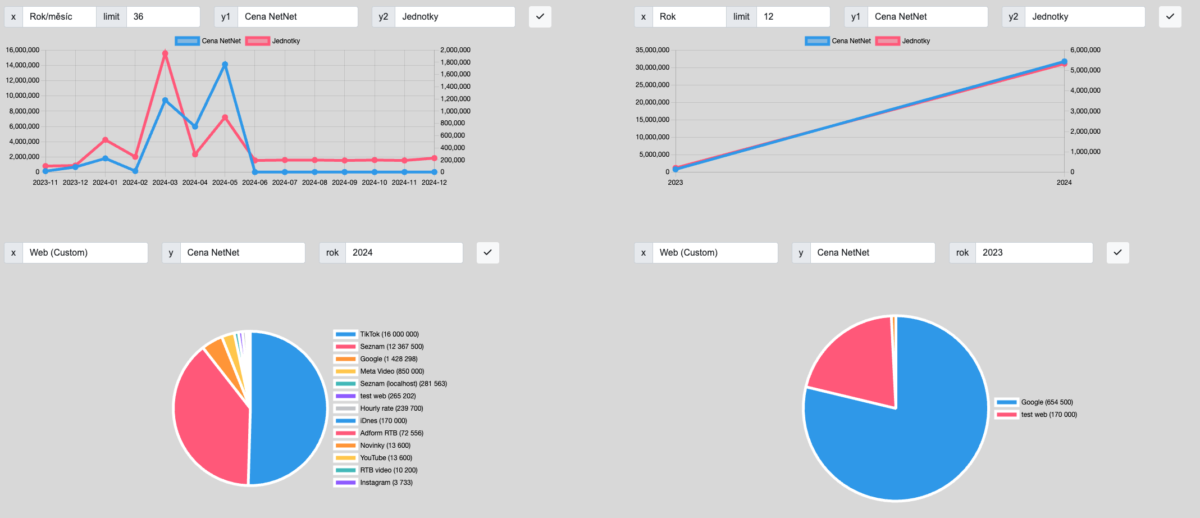
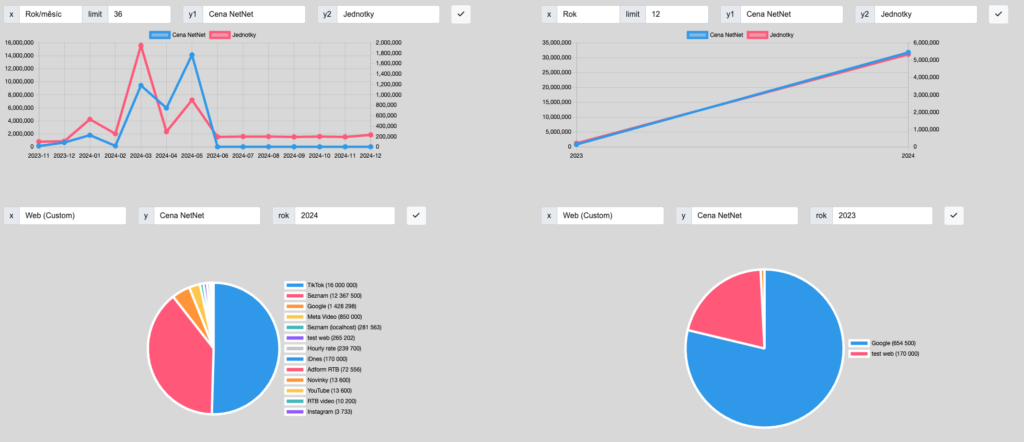
SPLIT DAT
Data můžete nyní rozdělit podle mnoha kritérií od Dodavatele, Klienta, Webu, přes Roky a Měsíce, až po názvy, Stavy kampaně, Buying modely či Nákupní VS Prodejní stranu (viz screenshot níže)
FILTROVÁNÍ DAT
Data, která vám vyjedou, si pak můžete ještě pokročile filtrovat, abyste tam měli pouze ty hodnoty, které vás zajímají, viz screenshot níže:
Výsledná data máte jak v přehledné tabulce, kterou je možné exportovat tlačítkem Exportovat pod ní, jsou k dispozici i krásné grafy s možností zobrazování různých metrik.
NASTAVENÍ MODULU SPENDY
Nový modul SPENDY pracuje na logice H3.0 METRICS. Předesíláme, že modul H3.0 METRICS je vzhledem k jeho nákladnosti placeným modulem a je nutné mít aktivační klíč H3.0 METRICS.
V H3.0 METRICS nastavíme posílání vybraného balíku dat pro modul SPENDY do patřičné tabulky databáze. To nám umožní pracovat v modulu SPENDY s různými balíky dat a přepínat mezi nimi.
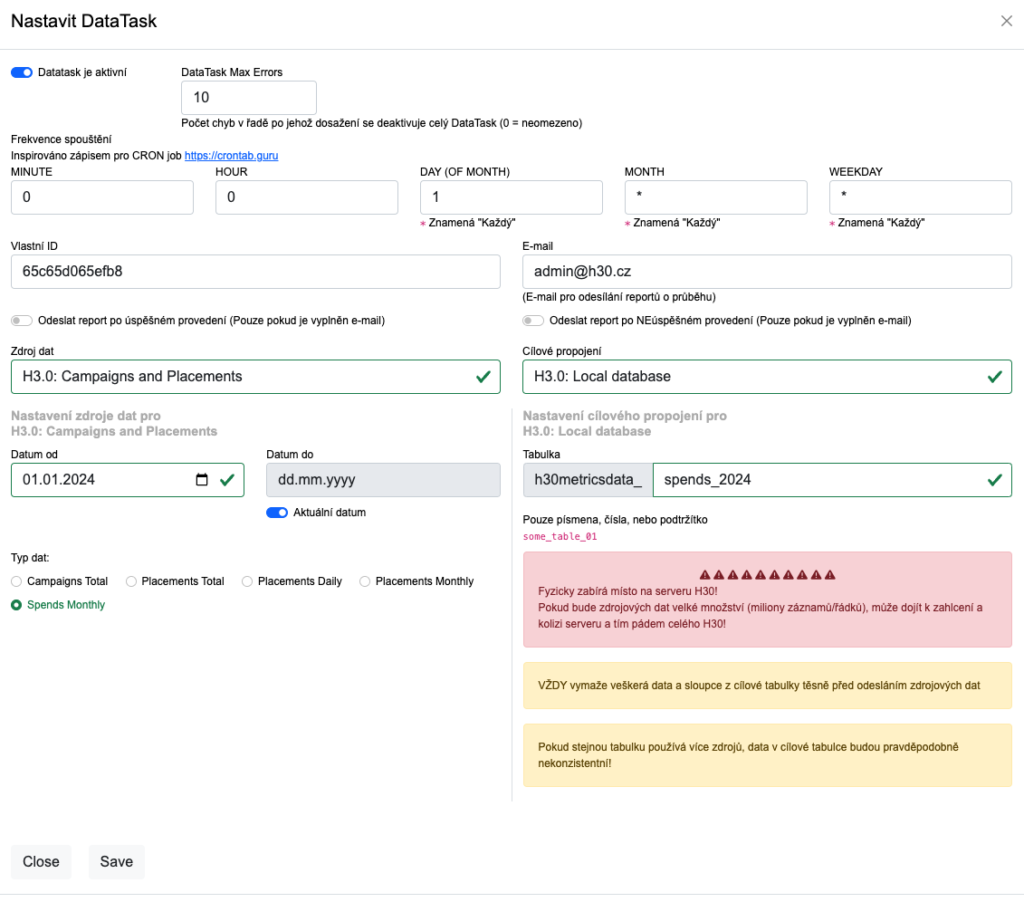
Nejdříve nastavíme, aby se nám posílaly data z H3.0 do patřičné tabulky v H3.0 databázi. Vytvoříne mový Data Task s následujími parametry: Zdroj dat: H3.0: Campaigns and Placemens Typ dat: Spends Monthly Ostatní si nastavte jak potřebujete. Takto můžete například vytvořit balík dat pouze pro současný rok, aby se vám v tom pracovalo rychleji.
Jako Cíl dat vyberte H3.0: Local database a vyberte si jak se bude jmenovat cílová tabulka. Tak bude i nazvaný balík dat v modulu Spendy.
Uložte si Data Task a počkejte na jeho spuštění dle plánu, nebo ho spusťte ručně.
Až DataTask doběhne, budete mít v záložce Spendy 2 (H30metrics) novou podzáložku s názvem tabulky, kterou jste právě vytvořili. Vyberte ji kliknutím a pak si již můžete hrát s daty SPENDŮ jak je libo.
Pro to, abyste mohli H3.0 propojit s Adformem je třeba požádat u Adform supportu o to, aby vám na váš agenturní přístup aktivovali API loginy a oni to udělají. Nezapomeňte je požádat, aby u těch API loginů povolili následující “scopes” :
Loginy, které se sestávají z Client ID a Client Secret a můžete tahat data z Adformu do Postbuy v H3.0, nebo posílat data z Adformu přes H3.0 do Google Big Query přes modul H3.0 METRICS.
Loginy se zadávají v Administrace/Nastavení/Propojení s ostatními systémy – kde v sekci Adform kliknete na tlačítko Nový a vyplníte přihlašovací údaje.
Nezapomeňte i těmto API loginům přiřadit patřičné klienty, aby se pod nimi zobrazovaly jejich kampaně.
Nový zásadní pilíř H3.0 nazvaný “H3.0 metrics” umožňuje přesouvat různá data pomocí H3.0 do jiných databází, aby s nimi bylo možné pracovat například při datové vizualizaci.
Jedním z modulů H3.0 metrics je H3.0 -> GBQ, tedy modul umožňující pravidelně aktualizovat data o kampaních v H3.0 do Google Big Query databáze.
Jak se takové propojení nastaví?
Nejdříve si nastavíme Google Big Query (GBQ), poté s GBQ propojíme H3.0 a nakonec řekneme H3.0, aby do GBQ pravidelně posílal data.
GOOGLE BIG QUERY
založte nový projekt v Google Big Query
V GBQ / SQL workspace si otevřete data projektu a založte Data set pro H3.0 data, papříklad (H30metrics)
v Datasetu su vytvořte tabulku. Můžete si je vytvořit rovnou 3, protože máme 3 typy tabulek: kampaně celkem, placementy celkem a pokud jste opravdu blázni a chcete riskovat obrovské množství dat a všechny problémy, které s tím mohou nastat, tak i placementy daily. Tedy v našem testovacím případě vytváříme 3 tabulky: – h30campaignstotal – h30placementstotal – h30placementsdaily
A tím pádem máte nastavení GBQ hotové.
PROPOJENÍ H3.0 A GBQ
Do H3.0 vložíme loginy do Google Big Query, aby se systémy mohly domlouvat.
V Administrace/nastavení/Propojení s ostatními systémy nascrollujeme dolů až na oddíl Google Big Query a klikneme na Nový. V otevřivším se okně je vždy alespoň nějak aktualizovaný návod, nicméně je třeba:
V Google Consoli v daném projektu v IAM and admin / Service account vytvořit Service Account, dát mu patřičná práva (potřebuje i zápis, takže optimálně všechny). Tento account bude potřebovat H3.0 pro přístup.
E-mail tohoto service accountu vložte do pole GBQ login formuláře e-mail v H3.0
Pro Service account vytvořte “Key”, typ .json a ten si stáhněte a vložte ho do H3.0 formuláře.
Zvažte, jestli login budou mít přístupni všichni H3.0 uživatelé s povoleními pro GBQ loginy a pokud ano, tak v H3.0 ještě vlevo nahoře zaškrtněte přepínač Veřejné.
Klikněte na Save, poté si ten login přes Open znovu otevřete a vlevo nahoře klikněte na tlačítko Test. H3.0 se zkusí připojit do GBQ a pokud bude vše OK, nahlásí 2x zelené OK. Pokud tam bude něco červeně, udělali jste někde chybu. Nezoufejte a napište nám, zkusíme vám poradit.
A teď už nám jenom zbývá nastavit proudy dat z H3.0 do GBQ
H3.0 -> GBQ
V modulu Administrace/H3.0METRICS se nastavují takzvané DataTasky, tedy úkoly pro H3.0, aby posílalo nějaká data jinam. V našem případě nastavíme 3 datatasky pro posílání Kampaní celkem, Placementů celkem a Placementů po dnech, pokaždé do jiné tabulky v GBQ, kterou jsme si předtím nastavili.
Klikněte na tlačítko Vytvořit nový DataTask
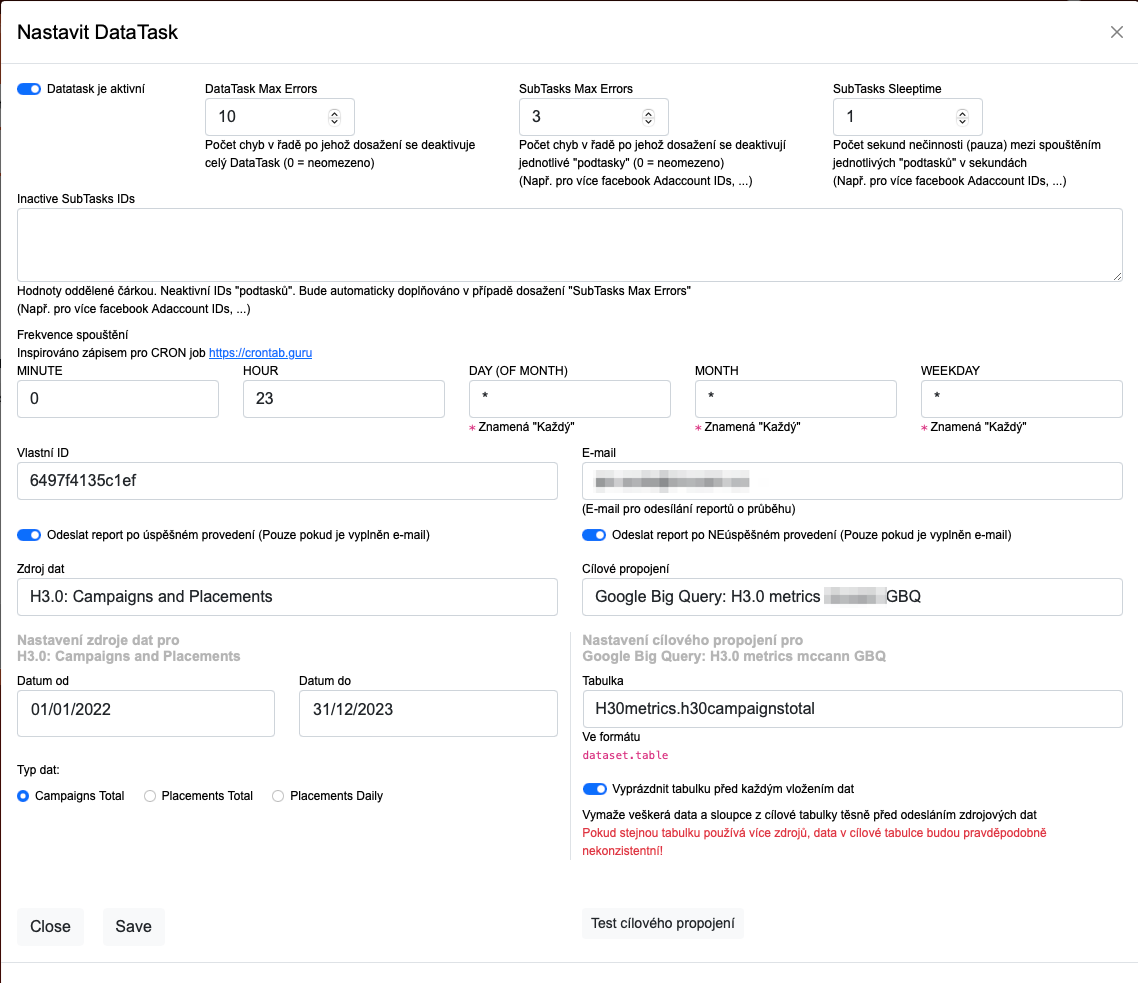
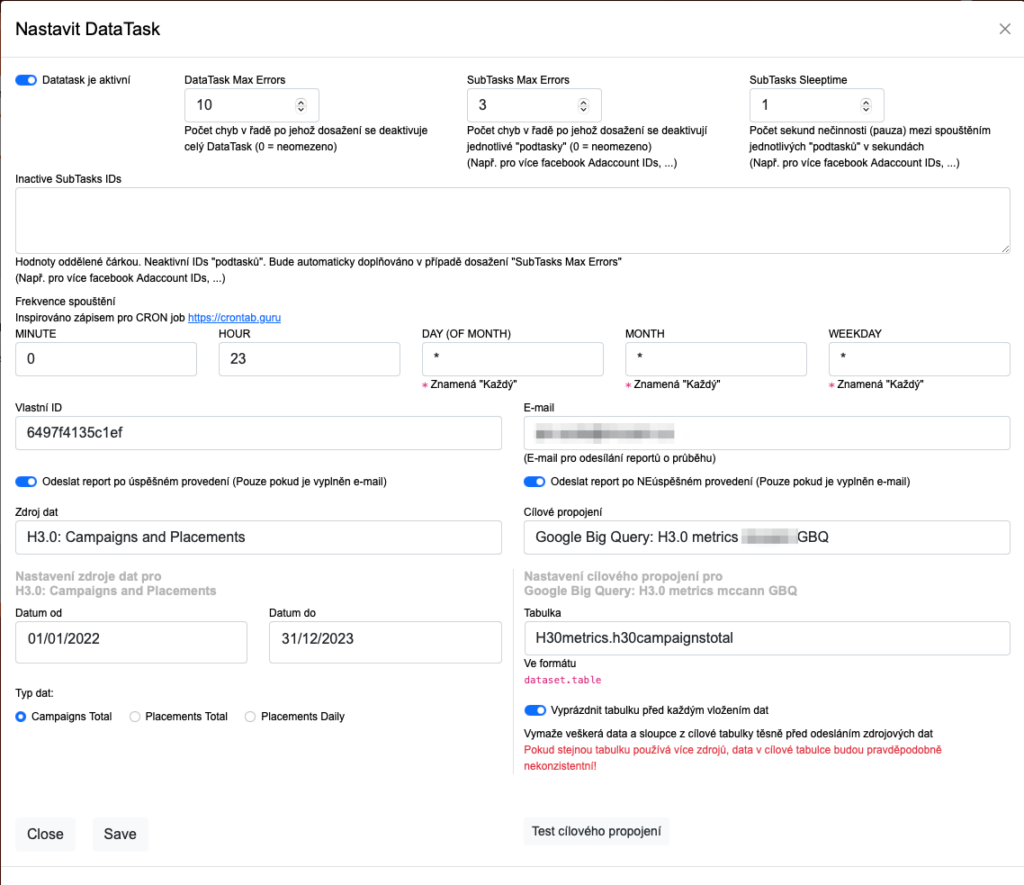
V okně, které se otevře je možné DataTask nastavit. Je tam toho hodně, ale to nejdůležitější co potřebujete je:
Zdroj dat vyberte jako H3.0: Campaigns and Placements
Cílové propojení vyberte ten login, co jste si teď zadali
Vyberte Typ dat podle toho, jaká data chcete posílat (Kampaně celkem, Placementy celkem, Placementy po dnech)
Do Tabulka vyplňte název patřičné GBQ tabulky pro daný Typ dat. POZOR!! ve formátu dataset.table, tedy pro náš příklad třeba “H30metrics.h30campaignstotal”
Můžete si kliknout na tlačítko Test cílového propojení, abyste zjistili, že máte loginy i Tabulku napsané správně
Zaškrtněte Vyprázdnit tabulku před každým vložením dat
Nastavte správně Frekvenci spouštění, pokud chcete každý den v nějakou hodinu, musí být v DAY, MONTH i WEEKDAY hvězdička a v MINUTE a HOUR patřičná hodina a minuta dne v kolik se to má spouštět
Pro úvodní odlaďování si nechte Odesílat reporty jak po úspěšném, tak po neúspěšném provedení
Nastavte správný datum Od a Do, pro vhodný časový úsek dat, která se budou posílat.
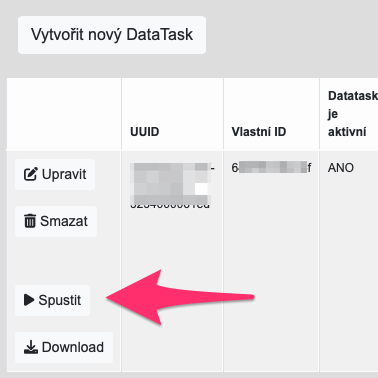
Klikněte na Save a nyní jenom zbývá počkat, až nastane patřičný okamžik, který jste nastavili v Data Tasku, aby se spustil.
Pokud byste nechtěli čekat, můžete Data Task spustit ručně kliknutím na tlačítko Spustit v řádku DataTasku v seznamu DataTasků.
Pozor – DataTasky se spouštjí “asynchronně”, tedy může trvat, než doběhnou, i když se vám třeba může zdát, že už proběhly. Výsledek toho jak DT proběhlo je v pravých sloupcích tabulky se seznamem DataTasků
A co dál? Můžete si vytvořit vlastní dashboard s daty z H3.0, například v Looker Studio (bývalé Google Data Studio).